Microservices in .NET part 2: Silver Bullets and Free Lunches?
June 11, 2015 1 Comment
I have spent the better part of this week digging into micro services and I love the idea. Here are some benefits I see that can be realized by using a microservices approach:
- The granularity level allows developers to stay on a single context while solving a problem. This singularity of focus makes it much easier to dig into the details of a specific object or set of objects. In many cases, it will quickly expose poor planning in an organization and provide rationale for fixing the process. As an example, a service that has a lot of churn is probably one that was not planned out well (not talking finding additional uses, but rather having to rebuild contracts and re-architect the service on a regular basis)
- The services are simple,making it easy to maintain the individual components.
- The methodology forces a good separation of concerns.
- You can use the best tool for the job rather than stick to a single platform, programming language or paradigm, etc. This is a dual edged sword, as I will uncover a bit later.
- Isolated solution problems can easily be fixed without much impact. If you find your employee microservice has an issue, you can fix it without deploying the entire solution.
- Working with multiple services enables the use of concepts like Continuous Integration (CI) and Continuous Delivery (CD). This is also dual edged, as you almost have to go to a full blown CD implementation to use microservices architectures. I will hit this later, as well.
- You can get multiple teams working independently of each other. This was always possible, of course, as I have pointed out in my Core As Application blog entries (one here), if you will take the time to plan out you contracts and domain models first. (NOTE: In 2010, I was told “you cannot design contracts first, as you don’t know all of the requirements up front”. By 2011, I proved this wrong by delivering using a contract first approach, both ahead of time and under budget – a bit of planning goes a long way).
- Systems are loosely coupled and highly cohesive.
This is just a short list of the benefits. The problem I see is everyone is focusing on the benefits as if we have finally found the silver bullet (do you have werewolves in your organization?) and gained a free lunch. This article focuses on some of the downsides to microservices.
DevOps
As you move to smaller and smaller services, there are many more parts that have to be deployed. In order to keep the solutions using the microservices up and running, you have to be able to push the services out to the correct location (URI?) so they can be contacted properly by the solutions using them. If you go to the nth degree, you could conceivably have tens, if not hundreds, of small services running in an Enterprise.
As each service is meant to be autonomous, this means you have to come up with a strategy for deployment for each. You also have to plan for high availability and failover. And there has to be a solid monitoring and instrumentation strategy in place. In short, you need all of the pieces of a good API Management strategy in place, and you need to do this BEFORE you start implementing microservices. And I have not even started focusing on how everything is wired together and load balancing of your solutions. On the plus side, once you solve this problem, you can tune each service independently.
There is a burden on the Dev side that needs to be tackled up front, as well. You need to start thinking about the requirements for monitoring, tracing and instrumenting the code base and ensure it is part of the template for every service. And you have to plan for failure, which is another topic.
As a final point on this topic, your dev and ops team(s) must be proficient in the combined concept of DevOps to have this be a success. Developers can no longer pitch items over to Ops with a deployment document. They have to be involved in joint discussions and help come up with plans for the individual services, as well as the bigger solutions.
Planning for Failure and Avoiding Failure
Services will fail. Looking at the plethora of articles on microservices, it is suggested you use patterns like circuit breakers (avoid hitting a failed service after a few attempts) and bulkheads (when enough “compartments” are “under water”, seal the rest of the solution from the failure point). This is a fine avoidance strategy, but what if the service failing is a critical component to the solution working?
Not mentioned in the articles I have read is a means of managing services after failure. Re-deploying is an option, and you can make redeployment easier using quickly set up virtual environments and/or containers, but what if reaching that portion of the network is the point of failure. I would love to hear comments on this next idea: Why not look at some form of registry for the services (part of API Management, similar to UDDI, etc.) or a master finder service that exists in various locations and that all applications are aware of. Another idea would be to include as part of the hyper-media specification backup service locations. But either of these solution further exacerbates the reliance on DevOps, creating even more need for planning solutions and monitoring released solutions.
I don’t see microservices working well without a good CI/CD strategy in place and some form of API management. The more I look into microservices the more I see the need for a system that can discover its various points on the fly (which leads me back to the ideas of using a finder service or utilizing hypermedia to inform the solutions utilizing microservices where other nodes exist).
Contracts and Versioning
When you develop applications as a single Visual Studio solution (thinking in terms of projects and not products?), you have the ability to change contracts as needed. After all, you have all of the code sitting in front of you, right? When you switch to an internal focus on services as released products, you can’t switch out contracts as easily. You have to come up with a versioning strategy.
I was in a conversation a few weeks ago where we discussed versioning. It was easy to see how URI changes for REST services required versioning, but one person disagreed when I stated changes to the objects you expose should be a reason for versioning in many instances. The answer was “we are using JSON, so it will not break the clients if you change the objects”. I think this topic deserves a side bar.
While it is true JSON allows a lot of leeway in reorganizing objects without physically breaking the client(s) using the service, there is also a concept of logical breakage. Adding a new property is generally less of a problem, unless that new element is critical for the microservice. Changing a property may also not cause breakage up front. As an example, you change from an int to a long as planning for the future. As long as the values do not exceed the greatest value for an int, there is no breakage on a client using an int on their version of the object. The issue here is it may be months or even years before a client breaks. And finding and fixing this particular breakage could be extremely difficult and lead to long down times.
There are going to be times when contract changes are necessary. In these cases, you will have to plan out the final end game, which will include both the client(s) and service(s) utilizing the new contract, as well as transitional architectures to get to the end game without introducing a “big bang” approach (which microservices are said to help us avoid). In short, you have to treat microservice changes the same way you approach changes on an external API (as a product). Here is a simple path for a minor change.
- Add a second version of the contract to the microservice and deploy (do not remove the earlier version at this time)
- Inform all service users the old contract is set to deprecate and create a reasonable schedule in conjunction with the consumers of the microservice
- Update the clients to use the new contract
- When all clients have updated, retire the old version of the contract
This is standard operating procedure in external APIs, but not something most people think about a huge deal when the APIs are internal.
I am going to go back to a point I have made before. Planning is critical when working with small products like microservices. To avoid regular contract breakages, your architects and Subject Matter Experts (SMEs) need to make sure the big picture is outlined before heading down this path. And the plan has to be conveyed to the development teams, especially the leads. Development should be focused on their service when building, but there has to be someone minding the shop to ensure the contracts developed are not too restrictive based on the business needs for the solutions created from the services.
Duplication of Efforts
In theory, this will not happen in microservices, as we have the individual services focusing on single concerns. And, if we can imaging a world where every single class had a service (microservices to the extreme?) we can envision this, at least in theory. But should we break down to that granlular a level? I want to answer that question first.
In Martin Fowlers article, he talks about the Domain Driven Design (DDD) concept of a bounded context. A bounded context is a grouping of required state and behavior for a particular domain. Martin Fowler uses the following diagram to show two bounded contexts.
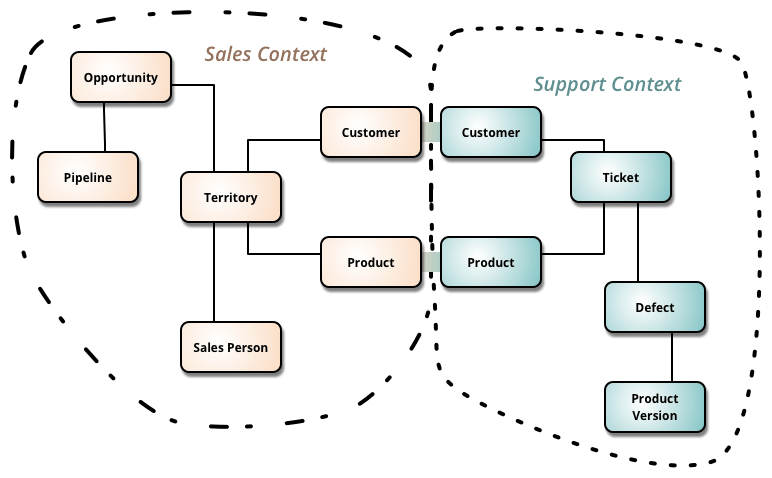
In the diagram above, you see some duplication in the bounded contexts in the form of duplication of customer and product. In a microservices architecture, you could conceivably move customer and product to its own service and avoid the duplication, but moving a concept out simply to avoid duplication is not the best motivation in all cases. If you can also make a customer or product business capability, I would wholeheartedly support this approach, but it is not always the case (another side bar).
When would you not want to separate out Customer and Product? In short, when the domain concept of these objects is different. In the sales context, a customer contains sales specific information, including terms of sale (net 60 days?) and other items that may not exist in a support context. If we are talking a company that ships products (as opposed to a service only company), we can add other contexts, like shipping and warehousing, that have radically different customer views. In the warehouse, a customer is completely unimportant, as they are focused on pulling orders. From a shipping standpoint, a customer is a name, a shipping address and a phone number. No need for any additional information. A customer microservice either spits out a complete object, allowing the services to filter (not a great idea from a security standpoint) or it provides multiple interfaces for each of the clients (duplication of efforts, but in a single service rather than multiple consumers and/or services, so it does not avoid duplication). A product can also be radically different in each of these contexts.
My advice to starting out is starting with bigger contexts and then decomposing as needed. The original “microservice” can act as an aggregator as you move to more granular approaches. Example of transitional states from the contexts above.
- Discover of duplication in the sales and support microservices leads to a decision the customer and product should be separate services
- New customer and product services created
- Sales and support services altered to use the new product and customer services
- new version of sales and support services created to avoid serving product and customer information
- Clients altered to use the new services as well as the sales and support services
This is one idea of migration, as we will discover in the next section.
Where do we Aggregate?
If we go back to the bounded context discussion in the last section, we see the need to aggregate. The question is where to we aggregate? You need to come up with a strategy for handling aggregation of information. I am still groking this, so I am not offering a solution at this time. Here are some options I can see.
Option 1 – Client: In a full microservices architecture, the client may be responsible for all aggregation. But what if the user’s client is a mobile application. The chattiness of a microservice architecture is hard enough to control across your internal multi-GB network infrastructure. Moving this out onto the Internet and cell networks expounds the latency. I am not saying this is a bad option in all cases, but if you opt for this approach, more focus on the latency issue is required from your mobile development team. On a positive note, if the client application can handle single service failures gracefully, you reduce the likelihood of a single point of failure.
Option 2 – Final service boundary: In this approach, the outermost service contacts the many microservices it requires to get work done and aggregates for the client. I find this more appealing, in general, for mobile clients. And it reduces the number of “proxies” required for web, simplifying the user interface client. As a negative, it creates a single point of failure that has to be handled.
Option 3 – Aggregation of dependencies: In this approach, the higher level service (closer to the client) aggregates what it requires to work for the client. At first, I liked this option the best, as it fits a SOA approach, but the more and more I read about the microservices idea, the more I see this as a potential combination of the bad points of the first two options, as you introduce numerous points of failure on the aggregate level while still potentially creating multiple points for latency in your client applications. I still think this might be something we can think through, so I am providing it.
If you can think of other options, feel free to add them in the comments.
Testing One, Two, Three
I won’t spend a lot of time on testability, but the more moving parts you have to test, the harder it is. To understand why this is so, create an application fully covered in unit tests at every level, but developed by different teams, and then integrate. The need for integration testing becomes very clear at this moment. And what if you are not only integrating multiple libraries, but multiple discrete, and very small, services. There is a lot of discipline.
I find the only reasonable answer is to have a full suite of unit tests and integration tests, as well as other forms of testing. To keep with the idea of Continuous Integration, only the smaller tests (unit tests) will be fired off with each CI build, but there will be a step in the CD cycle that exercises the full suite.
There is also a discipline change that has to occur (perhaps you do this already, but I find most people DON’T): You must now treat every defect as something that requires a test. You write the test before the fix to verify the bug. If you can’t verify the bug, you need to keep writing before you solve it. Solving something that is not verified is really “not solving” the problem. You may luck out … but then again, you may not.
Summary
There are no werewolves, so there are no silver bullets. There is no such concept as a free lunch. Don’t run around with hammers looking for nails.The point here is microservices is one approach, but don’t assume it comes without any costs.
As a person who has focused on external APIs for various companies (start ups all the way to Fortune 50 companies), I love the idea of taking the same concepts inside the Enterprise. I am also intrigued by the idea of introducing more granularity into solutions, as it “forces” the separation of concerns (something I find so many development shops are bad at). But I also see some potential gotchas when you go to Microservices.
Here are a few suggestions I would have at this point in time:
- Plan out your microservices strategy and architecture as if you were exposing every service to the public. Thinking this way pushes you to figure out deployment and versioning as a product rather than a component in a system.
- Think about solving issues up front. Figure out how you are going to monitor your plethora of services to find problems before they become huge issues (downtime outside of SLAs, etc). Put together a disaster recovery plan, as well as a plan to failover when you can’t bring a service back up on a particular node.
- In like mind, plan out your deployment strategy and API management up front. If you are not into CI and CD, plan to get there, as manually pushing out microservices is a recipe for disaster.
- Create a template for your microservices that includes any pieces needed for logging, monitoring, tracing, etc. Get every developer in the organization to use the template when creating new microservices. These plumbing issues should not requiring solving again and again.
- Articles in this series
- A foray into Micro Services in .NET
- Microservices in .NET 2: Silver Bullets and Free Lunches << this article
Peace and Grace,
Greg
Twitter: @gbworld































