Why Code Organization is so Important in Software
November 12, 2020 Leave a comment
I am a pattern person. This makes me great at reading and quickly memorizing maps. I can look at a Sudoku board and start mentally filling in without having to think about the numbers too much. I can also look at a software architecture problem, from a single application to integrated systems, and start figuring how to map from where we are to where we need to be. I can also see patterns in software development, not only in what we are doing, but the how and the why.
Today, software development is difficult. Some of this comes from the overly optimistic approach most developers take when sizing a task. Some of it comes from the practices we use. And others still come from business or how we interact with business. In this post, I want to take a look at why code organization is a foundational skill for developing quality maintainable and acceptable solutions.
First a bit of history …
Finding the Root
There are a few things I notice in various places I have consulted or worked over the years.
- There is very little testing over the code base.
- Refactoring is a luxury when there is
- Agility is “practiced” in the development team, but not throughout the Enterprise
- Very little is automated (in DevOps words, I see far more CI and far too little CD – a topic for another post?)
- There is too much technical debt in the solution
It is not that we don’t have knowledge of many practices that would alleviate these tendencies, it’s just that we have precious little time. This is partially due to our optimism, but also due to pressure of business compounded by the debt built up from the lack of time to refactor. And it goes on.
My first exploration into this topic came from working with my first DevOps assignment. How do you take an organization from fully manual deployment to the point where a code check in could potentially push all the way to production, in discrete, controlled steps?
I started from the end, production deploy, and walked back to the beginning, code check in, with the bookends – or start and end states – being fully manual deployment via documents to a fully automated deployment triggered by a code check in (another lovely topic for a blog post?).
Here are the steps to get from manual to fully automated (and, as you will see, the steps for getting development under control).
- Organize the Code Base
- Find seams in the code
- Add interfaces
- Refactor
- Add Tests
- Repeat this cycle
- Test – Ensure code is covered for acceptability
- Refactor
Repeat the first three steps, as needed - Productize the code base
- Create a CI build
- Create a CD build for Development
- Add in Feedback loops
Continue steps 5 through 7 until the pipeline is complete
As I spent more time with additional clients, and different issues, I found organizing the code to be the foundation for almost all of them. Here are my statements
- It is difficult to automate the delivery of software without properly organized code
- It is difficult to test for acceptability without properly organized code
- It is difficult to maintain an application without properly organized code
- It is difficult to modernize a legacy application without properly organized code
- It is difficult to add new features without properly organized code
In some cases, I would replace “difficult” with “impossible” or at least “nearly impossible”. So, how do we get to organization.
Mi CASA es su CASA
Around 2008, I was working with a client who wanted to build a web application with the same features as a desktop application they currently had. Having spent time in Enterprise software development, my first thought was this: If you are writing the web application in the same language as the desktop application, why do you need to write a new application?
It is still a valid question today. As a result of asking that question, I started thinking about developing a framework for software development. In 2010, I came up with a name: Core As Application. Succinct and expresses the fact our core business logic really is our application. Also hard to digest. Wanting a cool name like “scrum”, I shortened it to CASA (which still means Core AS Application). It took awhile, but I realized it was neither a framework not a methodology, but a model. Below is a copy of the model from 2018.

The main point here is the center circle is the beginning point when thinking about an application. It is built on top of domain centric objects (generally state only, no behavior) and any frameworks required. It is fronted by a means of presenting the core to a “user”, which can be a human or another system that will work in sessions of time. Is is back ended by some means of persisting, or preserving, the state between “users” sessions. And, it is topped by enough tests to ensure acceptability of the application from the owners and users of the application.
Key to the model is the idea that the core is linked to the presentation and persistence portions of the system via contracts. In most languages, you call these contracts interfaces. But using these contracts, or interfaces, is where you are able to do things like switching from SQL Server to Oracle, or making a new mobile application with identical features as your current website.
Yes, it gets a bit more complex, as you end up with multiple “cores” in the average system, as you have multiple “applications” or products (as shown in the diagram below where you have the website connecting to one or more APIs). It can also be taken to the point of extreme in microservices architecture.

The main rule is “each class goes into a library that is identified by its purpose and/or function”, you can start to see the value in adding the area of concern in the project, library and/or assembly names (with apologies using the word assembly if you are a non-.NET developer).
Something New?
Hardly. It is the idea of creating a taxonomy for your code. In the COM days, it was common to think of applications in terms of layers or tiers. Microsoft coined it n-tier architecture, although it was generally in three tiers (Client/UI, Business and Data – see below).

And the concepts align well with clean architecture, as you are starting from the business domain out.
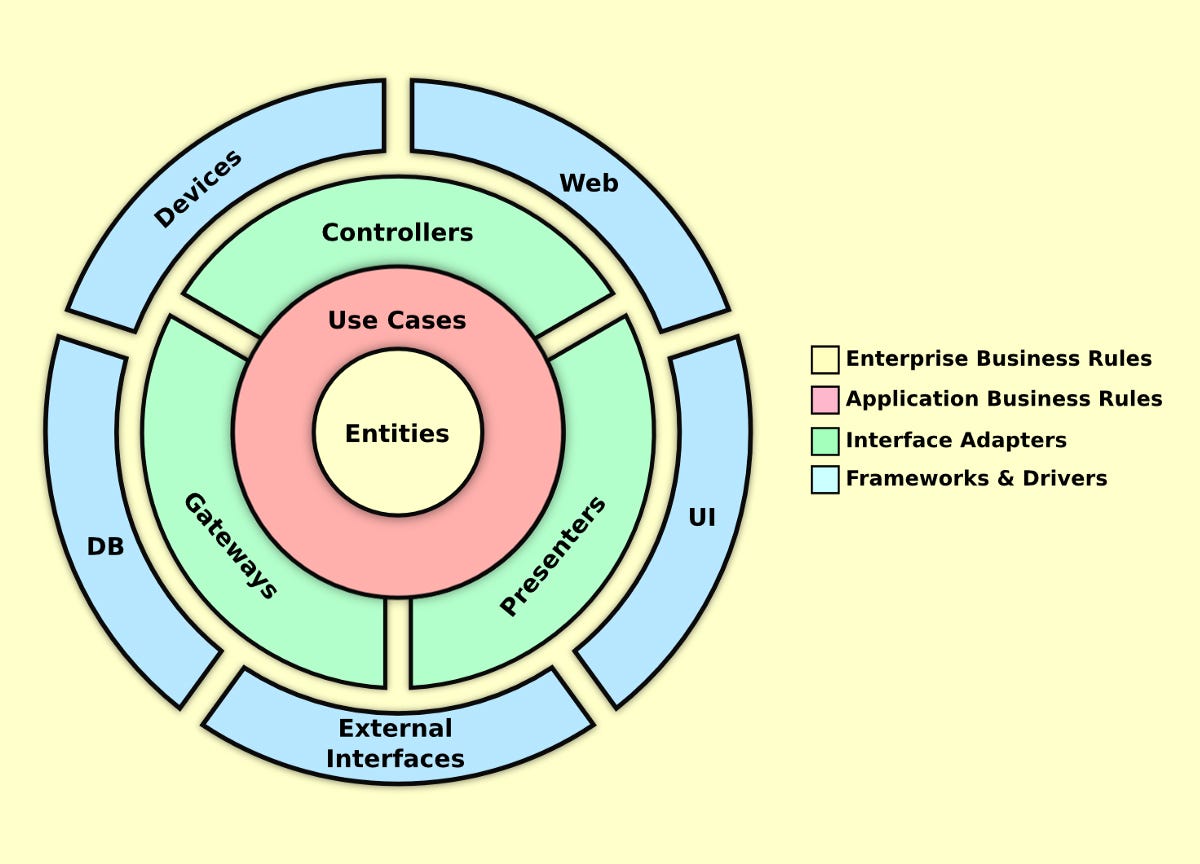
Think of the domain models at the bottom of the CASA model as Entities, the Core as Use Cases, the contracts and adapters as Controllers, Gateways and Presenters, and the outer points (presentation and persistence) as the blue outer circle in Clean Architecture (External Interfaces, DB, Devices, Web, and UI).
We can also see it in Hexagonal architecture (developed by Alastair Cockburn, one of the original Agile manifesto guys).
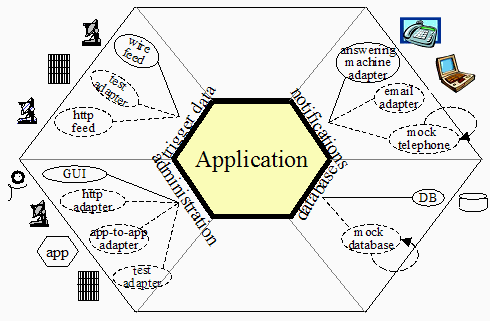
In Hexagonal architecture, the outside points are presentation and persistence, connected to the Core via ports and adapters. As an even better view of Hexagonal architecture, here is one with a bit of an overlay of clean architecture.

The Setup
When I am consulting, one of the first things I do with a solution is add in the folders corresponding to the type of code. The folders set up are:
- Core: The core business logic, aka the “application”. These are behavior objects that contain code specific to the business.
- Data: This will contain any projects specific to data persistence mechanisms, like a database. In the .NET world, a SQL Server Data Tools project would be an example of what lies here. These are generally segregated out early to productize the database separately from the application so it can be an independent product (avoid “big bang” deployment).
- Domain: The domain entities and exceptions. These are state objects and general just getters and setters.
- Framework: These are behavioral in nature by can apply to multiple applications and possibly even multiple domains. I will eventually “retire” these from the application solution and create a product out of the library and put it in a package manager (NuGet for .NET). I will occasionally subclass this further. The primary example would be separating out utility from the core framework libraries.
- Utility – A general product focused on performing a specific cross-domain function. For example, a print library.
- Persistence: Behavioral objects related to persisting state between sessions. This will generally be repository objects over a database or service proxies to contact APIs.
- Presentation: This is where the application connects to “users”, which can be human or other systems. I subdivide this folder into specific types of presentation.
- API – a web based API endpoint, generally REST in current times. In the past, I have also called this service, but that can be confused with a server based service.
- Desktop – A user interface to run on the desktop.
- Mobile – A user interface for a mobile device.
- Service – A server based service (think windows services).
- Web – A user interface using HTML or other web constructs, except APIs.
- Test – Anything related to automated testing of the application. The following subfolders are common, but I will have to write a more extensive post soon on testing, as there are different patterns one can take.
- Accept – Tests focused on acceptance. While one can cover a great deal of acceptability of the solution in unit and integration tests, these would be focused more on acceptance. An example might be Fitnesse. In general, automate everything you can here so user acceptance is more focused on preference of layout, colors, etc.
- Integ – Tests for integration. In these tests, actual dependencies are utilized rather than mocks. It should be noted the unit tests will be identical in signature to integration tests, but will utilize mocked dependencies. NOTE: Tests in products like selenium will fall into the Integration folder if they are included in the solution.
- Load – Tests for load testing. This is where load specific tests would be if you include them in the solution.
- Unit – Tests focused on testing a unit of code. All dependencies will be mocked with known return values. It should be noted the integration tests will be identical in signature to unit tests, but will utilize the actual dependencies.
As you go through the above list, you should note the two in bold italics. There are the types of projects you productize and remove from solutions. The data projects will become automated database deployment and changes should be completely decoupled from deployment of applications (in other words, you should take small steps in data changes and do them ahead of application deployment rather than create a need to deploy at the same time). The Framework should move out so they can be independently updated and packaged for all applications that use them.
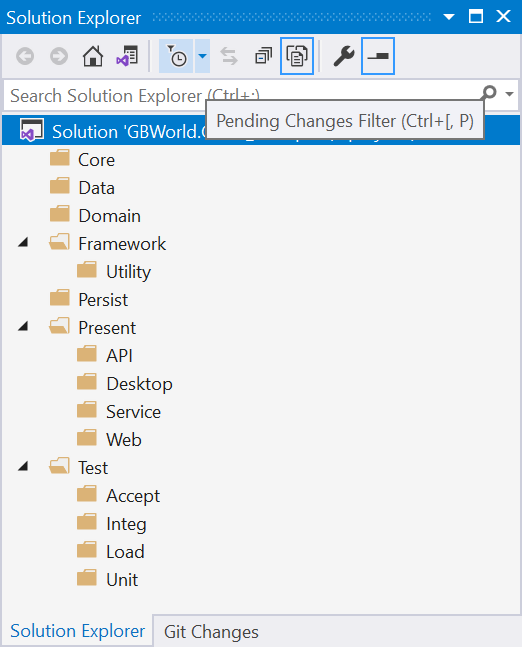
How does this look in development? Below is an empty solution in Visual Studio with the folders.
In Practice
The practice varies slightly between green field (new development) and brown field (currently deployed development) solutions. Let’s look at each independently.
Green Field
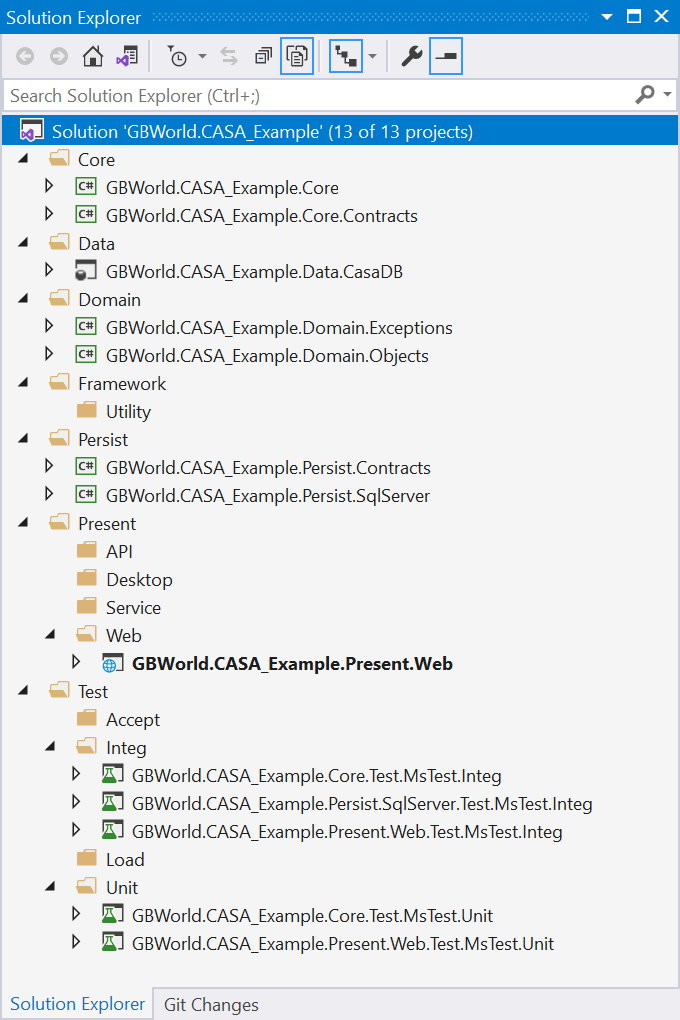
With green field development, I will start by creating the various projects in the solution in the proper folders, as shown below.
The general naming convention is:
Organization_Name.Product_Name.Area.SubArea
In this naming convention, the area is the folders: Core, Domain, Persistence, Presentation and the like.
It takes a bit more time, but I like to match up my code folders in the solution with the file system. This is done as follows.
Create the New Project by selecting the folder it will go in, right clicking and choosing add project.

Add the correct type of project. In this case, I am setting up the Core business logic in .NET Core (unintentional play on words?).
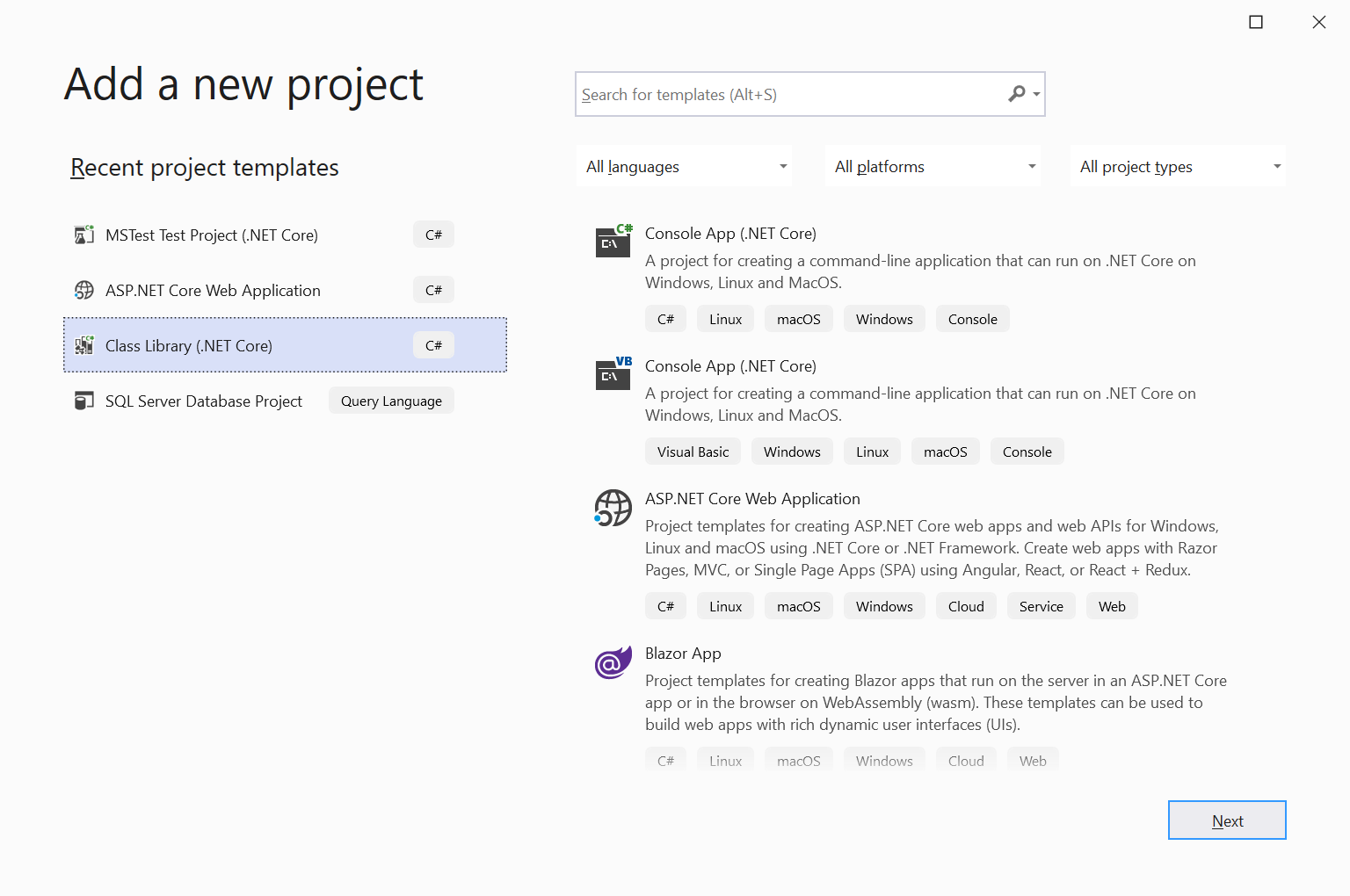
Name the project. In this example, it is the Core project for the CASA_Example product. Note that the folder is changed (highlighted).

Once I am done, all of the projects will be in their correct folders, both on the file system (left) and in the solution (right).

Brown Field
If the brown field product was already organized and the team followed the practice religiously, there is nothing to do. But, if this is a solution that requires reorganization, you have some work. This is a huge topic and worthy of a blog post of its own. I will do this soon on a post on legacy modernization.
One common example would be a solution in which all, or nearly all, of the code was present in the user interface/presentation project. In this case, you have to start organizing the code. These would be the steps I would take to do this.
- Rename the presentation project. This is not completely necessary, but doing this and moving the project to the correct folder on the drive is a good first step, as it starts setting up the process in your team early. A few steps here.
- Go ahead and fix the namespace of the files in this project now. This is not mandatory, but it helps you avoid having to fix using statements later. This may take a bit of time, but it pays to keep your library maintained.
- Double check naming on custom folders and adjust this now, as well.
- Search for boundaries/seams in the code. The natural seams are:
- Any code that access a persistence mechanism
- Any code that has core business logic (use cases)
- Any code that serves a utility (or helper) function
- Migrate this code into a folder in the project with the proper area name.
- Create an interface for the new class. This is your contract.
- Create tests.
- Refactor. You may have to run back over different steps above at this time.
- Repeat steps 1-3 until you have all code that is not presentation related segregated. I start from persistence, then to framework, then to core, etc. The idea is migrate out the dependencies that are farther out in the clean architecture diagram first (or focus on the far right of the CASA model first.).
- Migrate code to new projects in the proper areas. Scroll back up to green field to see how to do this.
- You may, again, have to iterate.
I will focus on a post on legacy modernization of .NET applications some time soon to go through all of these.
Discussion
I have done this exercise with various companies with a lot of success. It is a bit difficult to get used to at first, but once the team is used to the concept, it flows nicely. It also gives a nice model to set up where code should go and makes it very easy to find the source of a problem with the code base.
When I introduce this concept, I get a few questions on a regular basis.
How strict should I be to adhering to names in my projects, namespaces, etc.? This is a naming convention. Like any naming convention, you should be very strict to using it consistently. It should be part of your code reviews like naming classes.
But do I have to use the names Core, Domain, Persist, Present, etc.? Honestly, I don’t care if you name it Fred, Wilma, Barney, and Betty, as long as the names make sense to you. I will state, however, I think Flintstones names are stupid, but mostly because it becomes another thing to train new developers on. I can see eyes rolling when you say “In this company, the core business logic is called Fred because Fred was the head of the Flintstone household.” Whatever floats your boat. 😀
I had a client want to change Present, Core, and Persist to UI, Business, and Data. I don’t particularly like these names, as not all presentations are user interfaces, not all persistence is through data storage mechanisms, and using the three sounds very n-tierish. But, it was what they wanted.
I had another client who asked if Core could be App, for application. I was fine with this. I prefer not to, as I feel Core is a better representation of “core business logic”, but if you regard this an Application, or App, role with it.
The important part is be consistent and be rigorous in upholding your standards. When you get loosey goosey on this one, you start making it more difficult to maintain your code base and you return to square one. You also risk introducing technical debt when you move away from consistency.
Can I use Clean Architecture? Sure. This would mean using the following folders.
- Enterprise
- Entities (instead of domain)
- Application
- UseCases (instead of core)
- InterfaceAdapters
- Controllers
- Gateways
- Presenters
- Framework
- Web
- UI
- ExternalInterfaces
- DB
- Devices
The thing I am not completely sold on here is the Presentation and Persistence are both under the Framework area and it muddies the word Framework, as the .NET Framework would be completely different from your website.
But, if this is how you want to do it, that is your choice. You can do the same with Onion Architecture or Hexagonal Architecture.
Summary
Code organization is one of the issues I see most often with clients. This goes in the direction of single monolithic solutions or very granular solutions to ensure the code can be found for maintenance. Very seldom do I find code organized in a way it is very easy to maintain.
Once your code is divided into proper spheres of influence, you will still have to take some additional steps to complete the maintainability of the solution. Tests are a key component, as is determining the names for different types of classes. As an example, do you call a core class that acts as a pipeline for a particular type of information a manager, a service, or something else.
Peace and Grace,
Greg
Twitter: @gbworld
